~16 minute read
The Two Perspectives
A Position Paper on AI Readiness for the Small and Mid-Sized Business
Our advice
Start with Paper Zero — find yourself first.
Before the frameworks land the way they’re meant to, see which of the five financial personas is running your business today — Which Financial Persona Is Running Your Business? is the recognition on-ramp: find yourself first, then read on. From there, The Two Perspectives names the disciplines — knowledge governance and operational data integration — that determine whether AI produces operating intelligence or expensive theater. The papers below build from that diagnosis to the lab result that tests it.
Reading order
- ★ Which Financial Persona Is Running Your Business? — find yourself first, then read on. ~13 minutes.
- The Two Perspectives — the AI-readiness diagnostic. ~16 minutes.
- Tax Ready Bookkeeping + The AI Stack — the bookkeeping-specific application. ~29 minutes.
- The CFO Operating System — the Stage-4 advisory layer; what clean books are for. ~15 minutes.
- ProjectBits Thought-OS™ — the full methodology umbrella. ~9 minutes.
- AI Debt: The Tax on Small Business — the cost of deploying AI without naming the decisions first. ~22 minutes.
- The Five Questions Test — the lab result: why clean books beat AI infrastructure. ~22 minutes.
- The Hill-Climbing Machine — the ecosystem view: what Satya Nadella got right, and the SMB foundation he skipped. ~20 minutes.
- The Third Perspective — People, Preparation & Readiness; the human discipline behind the harness, for change-management professionals. ~30 minutes.
- The Managed Initiative — the governance capstone: run an AI initiative the way product teams run products, translated for the $5M–$25M owner. ~30 minutes.
- Signal Clarity. Owner Amplification. — the owner’s time is fixed; the return on it is not. The governing layer that amplifies the owner’s judgment, proven on the practice’s own pipeline. ~28 minutes.
Bottom line up front: methodology and operational data are the two disciplines that determine whether AI investment produces operating intelligence — or expensive theater. This paper names both: knowledge governance (a governed, accessible digital corpus to ground the AI) and operational data integration (entity-resolved data so the AI can answer questions about current state). Together they are the readiness diagnosis every downstream paper builds on. Paper #1 in the Thought-OS™ reading order.
Don Lovett, Fractional CFO & Managing Principal · ProjectBits Consulting · June 2026
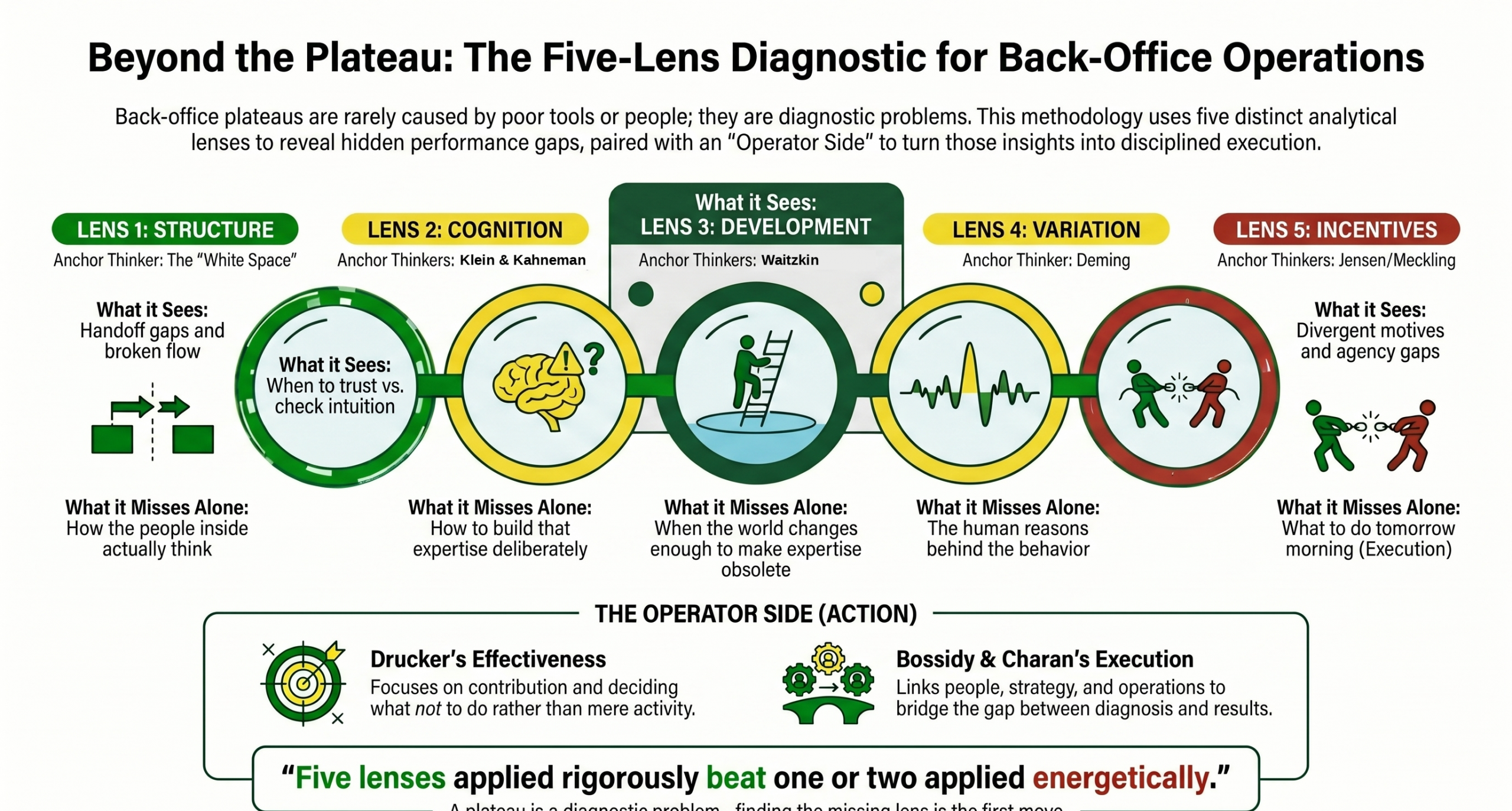
Beyond the Plateau: the Five-Lens Diagnostic for back-office operations — Structure, Cognition, Development, Variation, and Incentives — the diagnostic posture this paper argues determines whether AI produces operating intelligence or expensive theater.
The market problem
A small or mid-sized business owner in 2026 is being sold AI the way they were sold ERP in the 2000s and cloud in the 2010s: as if the tool itself is the value. Vendors demonstrate impressive capabilities on clean demo data, quote pricing that looks manageable, and frame the decision as "are you adopting AI?" rather than "is your business ready to extract value from it?"
The pattern is familiar to anyone who watched the earlier cycles. Tools get bought. Pilots get launched. Champions get appointed. Six to twelve months later the conversations sound the same: the AI gave us a confidently wrong answer; we can’t tell where its information is coming from; it works for one department but not the others; we spent the budget and we’re not sure what we got.
These outcomes are not failures of the tools. They are failures of the information environment the tools were dropped into. AI applied to fragmented data, undocumented methodology, and ungoverned content produces precisely the output you would expect: confident answers that occasionally hit, frequently miss, and are difficult to trust enough to act on.
A useful frame: the business’s data flow is the mill, the AI is the miller’s apprentice, and the daily flow of transactions, interactions, and decisions is the grain. The disciplines this paper describes are what turn grain into something usable — insight that can be acted on with confidence. Most AI vendors ship you the oven and forget the mill.
The thesis of this paper is direct: SMBs cannot realize AI value from tooling alone. Two parallel disciplines — knowledge governance and operational data integration — determine whether AI produces operating intelligence or expensive imitation of it. The same disciplines that make a business tax-ready make it AI-ready. The same disciplines that produce a clean year-end close produce a useful AI agent. SMBs that invest in the disciplines first, and the tooling second, succeed. SMBs that invert that order generally don’t.
Why this position exists
ProjectBits Consulting has been advising on IT infrastructure, financial systems and operations, and now AI integration since November 2005 — twenty years of engagements spanning public-company scale (Logitech, Brocade) down to consulting and advisory firms of fewer than 20 people, applied first within professional services on QuickBooks Online, trades and field service, and small financial services and real estate practices. The connecting thread across that work is ProjectBits Thought-OS™, the methodology that has evolved to guide ProjectBits engagements, books, and programs. Thought-OS™ applies Carnegie Mellon SEI’s Capability Maturity Model to financial operations and the adjacent disciplines that govern them. Its target is deliberate process and predictive outcomes: a structured way of thinking about how a business turns messy reality into trustworthy decisions, applied to one operational domain at a time.
The methodology is built on a simple operating principle: the financial discipline that survives an IRS audit is the same discipline that produces a reliable monthly close, clean cash forecasting, and operational decision support. The first published application is Tax Ready Bookkeeping™, which takes a business through the first three stages of operational maturity. Records discipline isn’t only a compliance exercise. It’s the foundation that lets every other operational capability work on top of it.
Two perspectives. One underlying discipline. This paper makes the case that an SMB owner evaluating AI investment should be looking at the capabilities and disciplines, not just the tools.
The two perspectives
Perspective one — knowledge governance
The first perspective is the methodology side: how a business captures, organizes, and maintains the knowledge that defines how it operates. Policies, procedures, templates, exemplars, case histories, definitions, methodologies, and decisions all live here.
Most SMBs have this knowledge, but not in retrievable form. It sits in the founder’s head, in scattered Word documents on shared drives, in email threads with senior staff, in slide decks from training sessions five years ago. The full collection of this material — what we’ll call the business’s corpus, from the Latin for "body of work" — exists. The discipline and techniques to make it useful don’t.
Think of the corpus as the business’s working library. Most SMB libraries look less like a curated collection on labeled shelves than a basement full of unsorted boxes: the material is there, but no one can find what they need under deadline pressure, no one is sure which version is current, and the person who knew where everything was left the company two years ago.
A useful corpus has four asset classes:
- Decisions — policies, procedures, rules, standards, methodologies. The explicit "how we do it."
- Patterns — templates, exemplars, playbooks. The gold-standard outputs the business produces.
- Cases — engagement records, project archives, what-we-did-for-Client-X-and-why. Pattern-matching fuel.
- Concepts — glossary, frameworks, methodology terms, domain vocabulary.
What turns a pile of documents into a usable corpus is governance — the discipline that the records management field developed over thirty years for compliance purposes, applied here for operational and AI purposes:
- Canonical declaration. For each topic, one document is the authoritative master version — what records professionals call the canonical source — and all other documents on the same topic are explicitly marked as superseded. Multiple sources of truth produce contradictory retrieval.
- Effective dating and supersession. Every asset has an effective date and explicitly supersedes its predecessor.
- Classification and metadata. Every asset is tagged with type, scope, authority level, sensitivity, and review cadence.
- Audit trail. Every change is logged. When the business gives a different answer this quarter than last, there’s a record of why.
- Retention and disposition. Stale content leaves the corpus. Stale documents in an AI system produce confidently wrong answers.
The international records management standard, ISO 15489, names four characteristics records need — authentic, reliable, integrity-bearing, useable. Each one maps to a predictable AI failure when absent: drafts retrieved alongside finals, unverified content cited as truth, silent edits that shift answers week-to-week, and metadata-less files the system cannot tell apart.
The work of climbing this perspective is not technological. It is editorial. Curating, deduplicating, marking canonical, killing stale content. Most SMBs find that the first version of this work — the audit phase — produces value before any AI system is built. It surfaces where the business actually lives in knowledge held only in people’s heads, which is often a more urgent finding than anything the eventual AI produces.
Perspective two — operational data integration
The second perspective is the data side: the structured and semi-structured information that records what the business is currently doing. Accounting transactions, customer records, sales activity, support tickets, project status, payroll, marketing campaigns, web analytics, calendar events, email metadata, call logs.
Most SMBs have this data, but it lives in fifteen or twenty separate SaaS applications with no integration. The CRM knows about the prospect; the accounting system knows about the invoice; the support system knows about the ticket; the marketing platform knows about the email open. No system knows all of it. The joins are where value lives, and the joins don’t exist.
The disciplines that make this data useful are the data engineering equivalents of records management:
- Centralized staging. Data lands in one queryable place — typically a database or warehouse — refreshed daily from source systems.
- Entity resolution. The discipline of recognizing that the same business, person, or thing appears under different names across different systems — and formally declaring them the same. Acme Inc. in the CRM, Acme Industries in the accounting system, and acme.com in the marketing platform are one company; each gets a stable internal identifier that every system references.
- Master data management. Once entities are resolved, one record per customer, product, or employee is designated the trusted master version — the golden record — that every system references and that has a clear owner responsible for keeping it current. Without this, the same customer can have three different addresses or phone numbers across three systems and no one knows which is right.
- Semantic layer. A shared dictionary that gives business terms a single technical definition. Revenue, active customer, engagement, and similar metrics are defined once and used consistently — every report, every dashboard, every AI query draws on the same definition.
- Lineage and provenance. Every figure can be traced both back to its origin — which source system, which responsible owner, which date — and forward through the transformations that produced it. When a number changes, the cause is investigable.
Each of these has a direct counterpart on the records side. Canonical sources become golden records. Classification taxonomies become entity schemas. Audit trails become data lineage and provenance. Retention policies become data lifecycle management. Sensitivity labels become data classification. The field names are different; the underlying discipline is identical.
For an SMB, the appropriate version of this is not an enterprise data warehouse. It is a lightweight centralized staging layer (an open source Postgres database is usually sufficient) with daily ELT from five to eight source systems, manual entity resolution for ambiguous cases, and a handful of canonical SQL views for the metrics that matter. The point is not scale. The point is that the joins exist.
Why each perspective alone fails
A common pattern in SMB AI adoption is to invest heavily in one perspective and assume the other will follow. Both partial approaches fail in predictable ways.
Knowledge governance without data integration produces an AI that knows the methodology but cannot apply it to specifics. The system can answer "what is our standard onboarding sequence" but not "where is Client X in that sequence." It can explain "how we approach pricing" but not "what we charged similar clients last year." Methodology in a vacuum is generic advice with high-quality phrasing. It is better than no methodology, but it is not operating intelligence.
Data integration without knowledge governance produces dashboards no one interprets. The numbers are accurate. The trends are visible. The integration is sound. But the meaning of the numbers — what counts as good, what threshold should trigger action, what historical pattern this resembles — lives in the methodology corpus that hasn’t been built. Without the interpretive layer, dashboards become noise that the team checks less often each month until they stop checking entirely. Operations data without methodology is signal without sense-making.
Tooling without either discipline is the most expensive failure mode and the most common. A business buys a generative AI subscription, points it at SharePoint, and expects results. The system retrieves draft documents alongside finals, surfaces methodology from three roles ago, fabricates numbers that look like they came from the books but didn’t, and gradually erodes the staff’s trust until they stop using it. The tool is fine. The information environment was never prepared.
The recurring theme: AI does not create discipline. It exposes whether discipline already exists. A well-governed business gets useful AI quickly. A poorly governed business gets confident garbage at scale. The intervention point is upstream of the tool selection.
The unified architecture
When both perspectives are developed, they converge at a specific architectural point: the AI agent layer. The agent is the surface where decisions get made and where users interact; one level below sits the retrieval system — commonly called RAG, for retrieval-augmented generation — that pulls methodology from the corpus, alongside the query layer that pulls current state from the data stores. An agent that can answer operationally useful questions for an SMB needs three inputs simultaneously:
- Methodology — retrieved from the knowledge corpus. The business’s approach, policies, and accumulated case wisdom.
- Current state — queried from the operational data layer. The actual situation of the client, the transaction, the project, the metric.
- Policy — applied as a gate. What the agent is allowed to do autonomously, what requires human approval, what is out of scope entirely.
Each is necessary; none is sufficient. The agent that has methodology but no current state is a chatbot with high-quality opinions. The agent that has current state but no methodology is a query interface with no judgment. The agent that has both but no policy is a liability waiting for a deployment incident.
A point worth naming explicitly: this AI layer is layered, not load-bearing. It makes some capabilities practical that wouldn’t otherwise be — extraction at the source, classification at scale, anomaly detection, real-time scenario analysis. But the underlying disciplines run on their own when needed. The monthly close still closes if the AI is unavailable. The decisions still get made. What changes when the AI works well is speed, surface area, and signal-to-noise. What does not change is the discipline underneath.
A maturity ladder for an SMB working toward this state has roughly five rungs:
| Level | Knowledge governance | Operational data | What AI can do |
|---|---|---|---|
| L0 | Folders, no metadata | Spreadsheet exports | Generic chat; high hallucination risk |
| L1 | Document management with version control | Centralized staging from primary systems | Basic retrieval; useful for stable reference content |
| L2 | Records discipline: canonical, dated, classified | Entity resolution + master data | Reliable retrieval with provenance; reliable cross-system queries |
| L3 | Information governance with sensitivity controls | Semantic layer with defined metrics | Audience-aware retrieval; consistent analytics |
| L4 | Active capture loop with retrieval feedback | Operational intelligence with alerts and anomaly detection | Proactive surfacing of issues and opportunities |
| L5 | Living corpus continuously refined | Real-time integrated state | Policy-governed agents acting on behalf of the business |
The path through these levels is sequential, not optional. A business at L1 cannot skip to L4 by buying a more expensive AI product. The dependencies are real. What changes between levels is the kind of question the AI can reliably answer — and the kind of decision the business can responsibly delegate to it.
An aside for the technical reader. This is the Apple-versus-Cray pattern applied to a different layer. Cray built supercomputers that could do extraordinary things if you wrote the right code for them; Apple built systems where the structure made ordinary work reliable at scale. ProjectBits’ AI stack runs both modes by design — Sonnet at design time as the Cray-equivalent (translating a written policy into executable Rego, classifying transactions against a 51-criteria taxonomy, drafting case summaries from a transcript) and OPA at runtime as the Apple-equivalent (enforcing the resulting policy deterministically, every time, with an audit log). The methodology earns its keep by knowing which work belongs in which mode.
The ladder above describes the general pattern. ProjectBits’ Financial Maturity Staircase — Thought-OS™ applied to financial operations specifically — is a four-stage instance of the same structure: Sovereign (your data, your perimeter, your audit trail), Accurate (reconciled, dimensionally classified, documents linked), Leverageable (policy-as-code, classification engine, every AI suggestion and human override audit-logged), and Informing decisions (operating scorecard refreshed weekly). The Reasoning-Augmented amplification layer sits on top of all four. Each operational domain a business cares about — books, marketing, operations — gets its own staircase. The underlying maturity logic is constant.
What SMB-appropriate looks like
An important point of clarification: the levels described above do not require enterprise spending. The disciplines are scale-independent; the implementations should be sized for the business.
A pragmatic SMB target — call it the working floor — looks like this:
On the knowledge side: a documented methodology, canonical-source designation for the top thirty operational questions, effective-dating on all canonical assets, a metadata schema with type and scope and sensitivity and review cadence, a quarterly review cadence with a named owner.
On the data side: a centralized open source Postgres database, daily ELT from accounting plus CRM plus support plus one or two operational systems, manually maintained entity resolution for customers and projects, a handful of canonical SQL views for the metrics that drive decisions.
On the AI side: a retrieval system over the curated corpus, with provenance citations on every answer, plus query access to the data layer for current-state questions. Policy gates on anything that writes back to source systems.
This floor is designed to be reachable for an SMB inside a single quarter with focused effort. The ceiling — full agentic operations with cross-system intelligence — is a multi-year ambition. The path between is sequenced.
What this is not: a multi-million-dollar data warehouse build. Not an enterprise content management implementation. Not a custom-trained foundation model. The discipline is the work; the tooling is the easy part.
Receipts — the discipline applied to its own practice
The disciplines this paper describes are not theoretical for ProjectBits. They are the practice we run on the practice. The marketing strategy, methodology library, session history, client correspondence, and reference material that drive day-to-day decisions live in a curated retrieval system we built and maintain — the same architecture pattern this paper recommends, sized for a small consulting practice.
Concretely, what that looks like today (mid-May 2026):
A canonical-source-designated methodology corpus. Six governing documents — positioning, methodology, onboarding playbook, voice, brand kit, and the umbrella methodology page — each with explicit status (canonical / living / locked), supersession metadata, and review cadence. Older PDF versions of the cornerstone marketing document are explicitly marked as superseded and excluded from retrieval. Multiple sources of truth produce contradictory answers; we eliminated ours.
A multi-format intake pipeline feeding ten retrieval collections. Markdown, PDFs, EPUBs (technical books), meeting transcripts, web articles, AI-conversation exports, and bookmarked external material flow into a vector store carrying roughly 195,000 indexed chunks across collections for working sessions, conversation history, ingested books, industry news with time-decay weighting, and curated external reference material. The audit template’s four asset classes — decisions, patterns, cases, concepts — are how new material actually gets filed.
A session-history archive that compounds. Every working session is captured to a PostgreSQL log with topic, summary, and keyword indexes; 299 sessions logged to date, transcripts ingested with provenance metadata. New work begins by querying prior work. The point at which this stopped being a backup system and started being institutional memory was the point at which retrieval became faster than the colleague-asking it replaced.
A live entity-resolution layer. Contacts in the CRM, leads from outreach platforms, meeting participants, and email senders are reconciled to single canonical identities — the SMB-appropriate version of master data management, not an enterprise MDM rollout. A cross-system query for "everything we have on this person or company" returns one answer, not three.
A canonical service registry for the practice’s own infrastructure. What runs where, with what credentials, on what health endpoint, is stored in one queryable place — applied to the firm’s own operations, not just client engagements. The discipline doesn’t stop at the books.
What’s still incomplete — and we say so. The question-capture loop we designed for surfacing, scoring, and feeding back the questions that drive corpus value exists as an architecture specification. Meeting-transcript intake is live; the canonicalization, scoring, and gap-tracking layers are design specs, not running code. We are working through them the same way we would work a client through them — sequenced, measured, no leaping ahead. The retrieval store carries decades of accumulated correspondence and reference material, but the formal audit — canonical-source designation and metadata schema applied retroactively to legacy content — is an ongoing multi-month effort. The audit doesn’t get done; it gets maintained.
Why we show this. The architecture in this paper isn’t a sales pitch built from a whiteboard. It is the working specification of the system we use to run our practice. Anything we recommend, we have been operating against ourselves — long enough to know which parts hurt and where the corners get cut under deadline pressure. When we walk a client through the audit template, the diagnostic, or the maturity ladder, we are walking them through territory we have already crossed.
A diagnostic framework
A business considering AI investment can usefully self-assess against six questions before any tooling decision is made. The answers indicate where on the ladder the business actually stands — which determines what AI can plausibly deliver and what disciplines need to develop first.
Canonical sources — For the top twenty operational questions a staff member or client might ask, is there a single document that is the authoritative answer, or are there multiple overlapping documents in different locations?
Effective dating — When was your operational methodology last reviewed and dated? If a senior staff member left tomorrow, would the team know which version of any given procedure is current?
Entity resolution — Could you produce, in a single query, a list of every customer interaction across your CRM, accounting system, support system, and email for a given client over the last twelve months?
Metric definitions — If three staff members were asked to calculate "active customers" or "monthly recurring revenue" independently, would they produce the same number?
Provenance — When the business gives an answer to a client question, can you trace the answer back to the source document, the staff member responsible, the effective date, and any superseded prior position?
Policy clarity — For decisions the business makes routinely — accepting a client, pricing an engagement, approving an expense, escalating an issue — are the decision criteria documented in a form that a new staff member (or an AI agent) could apply consistently?
A business that answers yes to four or more of these is positioned to extract real value from AI tooling. A business that answers no to four or more is being sold a solution that is unlikely to survive contact with its information environment. The intervention is upstream.
The operating thesis
The position this paper takes can be summarized in five claims:
AI tooling does not create operational discipline. It exposes the discipline that already exists — or doesn’t.
Two parallel disciplines — knowledge governance and operational data integration — determine whether AI produces operating intelligence or theater.
These are not two separate disciplines. They are the same discipline applied to different artifact classes. A business that develops one is unusually well-positioned to develop the other.
The disciplines are scale-independent. SMB-appropriate versions exist and are achievable inside a single quarter to a year of focused work.
The point where AI investment starts paying off as a system — sustained operating leverage, not episodic productivity wins — is the point where both disciplines reach roughly Level 2 maturity.
For SMB owners reading this and recognizing their own situation: the right next step is usually not a tool evaluation. It is an honest assessment of where the business stands on the two perspectives, followed by a sequenced plan to climb the relevant ladder. The tooling decisions become much easier — and the tooling investments much more productive — when they follow that assessment rather than precede it.
This is where ProjectBits starts. The entry path is the Tax Ready Assessment — a no-obligation scored diagnostic across 51 criteria in 9 categories. It places your business on the Financial Maturity Staircase, surfaces the specific gaps that matter most, and produces a 90-day roadmap. Yours to keep whether or not you engage further; the diagnostic is real on its own. For businesses where financial operations isn’t the obvious starting point, a 20-minute conversation reaches the same diagnosis through different questions.
If the framing in this paper resonates with what you are seeing in your own business, that’s where to start.
Take the No-Obligation Assessment · Schedule 20 Min with Don
This paper is the first in the ProjectBits reading order. Read the series in order at projectbits.com/method. It is the AI-readiness diagnostic the rest of the series builds on.
ProjectBits Consulting · projectbits.com/method · Reston, VA. ProjectBits Thought-OS™ and Tax Ready Bookkeeping™ are trademarks of ProjectBits Consulting, Inc. This paper is published for practitioner and client education.