~29 minute read
Tax Ready Bookkeeping™ + The AI Stack
A Four-Stage Data-Flow Whitepaper · Version 1.2
Our advice
Start with Paper Zero — find yourself first.
Before the frameworks land the way they’re meant to, see which of the five financial personas is running your business today — Which Financial Persona Is Running Your Business? is the recognition on-ramp: find yourself first, then read on. From there, The Two Perspectives names the disciplines — knowledge governance and operational data integration — that determine whether AI produces operating intelligence or expensive theater. The papers below build from that diagnosis to the lab result that tests it.
Reading order
- ★ Which Financial Persona Is Running Your Business? — find yourself first, then read on. ~13 minutes.
- The Two Perspectives — the AI-readiness diagnostic. ~16 minutes.
- Tax Ready Bookkeeping + The AI Stack — the bookkeeping-specific application. ~29 minutes.
- The CFO Operating System — the Stage-4 advisory layer; what clean books are for. ~15 minutes.
- ProjectBits Thought-OS™ — the full methodology umbrella. ~9 minutes.
- AI Debt: The Tax on Small Business — the cost of deploying AI without naming the decisions first. ~22 minutes.
- The Five Questions Test — the lab result: why clean books beat AI infrastructure. ~22 minutes.
- The Hill-Climbing Machine — the ecosystem view: what Satya Nadella got right, and the SMB foundation he skipped. ~20 minutes.
- The Third Perspective — People, Preparation & Readiness; the human discipline behind the harness, for change-management professionals. ~30 minutes.
- The Managed Initiative — the governance capstone: run an AI initiative the way product teams run products, translated for the $5M–$25M owner. ~30 minutes.
- Signal Clarity. Owner Amplification. — the owner’s time is fixed; the return on it is not. The governing layer that amplifies the owner’s judgment, proven on the practice’s own pipeline. ~28 minutes.
Bottom line up front: this whitepaper traces how a small business turns raw financial transactions into decisions a fractional CFO can act on — across four stages of data flow — and the discipline that makes the AI underneath it trustworthy. It is the bookkeeping-specific application of the Two Perspectives readiness diagnosis: clean, governed books are the substrate everything downstream depends on. Paper #2 in the Thought-OS™ reading order.
Don Lovett, Fractional CFO & Managing Principal · ProjectBits Consulting · June 2026
Where this fits
This is the prospect-facing whitepaper for Tax Ready Bookkeeping™ and the AI Stack that runs underneath it.
Our advice: read The Two Perspectives first. Before this paper will land the way it’s meant to, your business needs to be ready to extract value from AI — and "ready" has a specific meaning. The companion position paper at projectbits.com/insights/ai-readiness/ (The Two Perspectives) names the two disciplines — knowledge governance and operational data integration — that determine whether AI produces operating intelligence or expensive theater. It is the prerequisite read. Owners who skip it and start here often hear "industry-aware classifier" or "policy engine" as features to evaluate; owners who read it first hear them as the specific tooling answers to a question they have already framed for themselves. The diagnostic in that paper takes ten minutes. The investment in this one is wasted without it.
Once The Two Perspectives has framed the question, this whitepaper is the bookkeeping-specific application of the answer. The broader methodology umbrella — ProjectBits Thought-OS™ — sits at projectbits.com/method/ for readers who want the full operating system context. The reading order in plain terms: (1) Two Perspectives → (2) this whitepaper → (3) Thought-OS™ overview if you want the full method. Each one is short. They build on each other.
Where the methodology comes from. Nothing here was invented from scratch. The maturity-model side draws on two anchors that sit alongside the five-lens diagnostic: the Financial Maturity Staircase is an application of Carnegie Mellon Software Engineering Institute’s Capability Maturity Model to financial operations — the same five-level structure SEI introduced for software engineering, recast for the disciplines that turn transactions into decisions — and knowledge governance draws on records-management discipline (ISO 15489 — the international standard’s four characteristics: authentic, reliable, integrity-bearing, useable**)**. The five analytical lenses come from a small set of thinkers whose work has aged unusually well: structure from Geary Rummler and Alan Brache (process / job / organization levels, "the white space on the organization chart"); cognition from Gary Klein and Daniel Kahneman (recognition-primed decision-making, System-1 / System-2 thinking, conditions for intuitive expertise); development from Josh Waitzkin (The Art of Learning, deliberate practice, smaller-circle refinement); variation from W. Edwards Deming (common-cause vs special-cause variation, plan-do-check-act); and incentives from agency theory (Jensen and Meckling). To these we add two operator-side frameworks: Peter Drucker on effectiveness and Larry Bossidy and Ram Charan on execution. Diagnostic discipline draws on Philip Tetlock’s calibration research (enumerated hypotheses, disconfirming evidence, named load-bearing assumptions, pre-mortem before action). The full treatment of the five lenses lives in the full five-lens methodology; the maturity-model treatment lives in the maturity-model overview. What ProjectBits adds is the integration: the financial-data application, the AI-stack architecture, the engagement playbook, and the receipts of having operated it on ourselves.
The grist mill — one image to carry through
One picture carries this whole document: the financial data flow is the grist mill. AI is the miller’s apprentice. People are the designers and operators. And flour is not the goal — bread is.
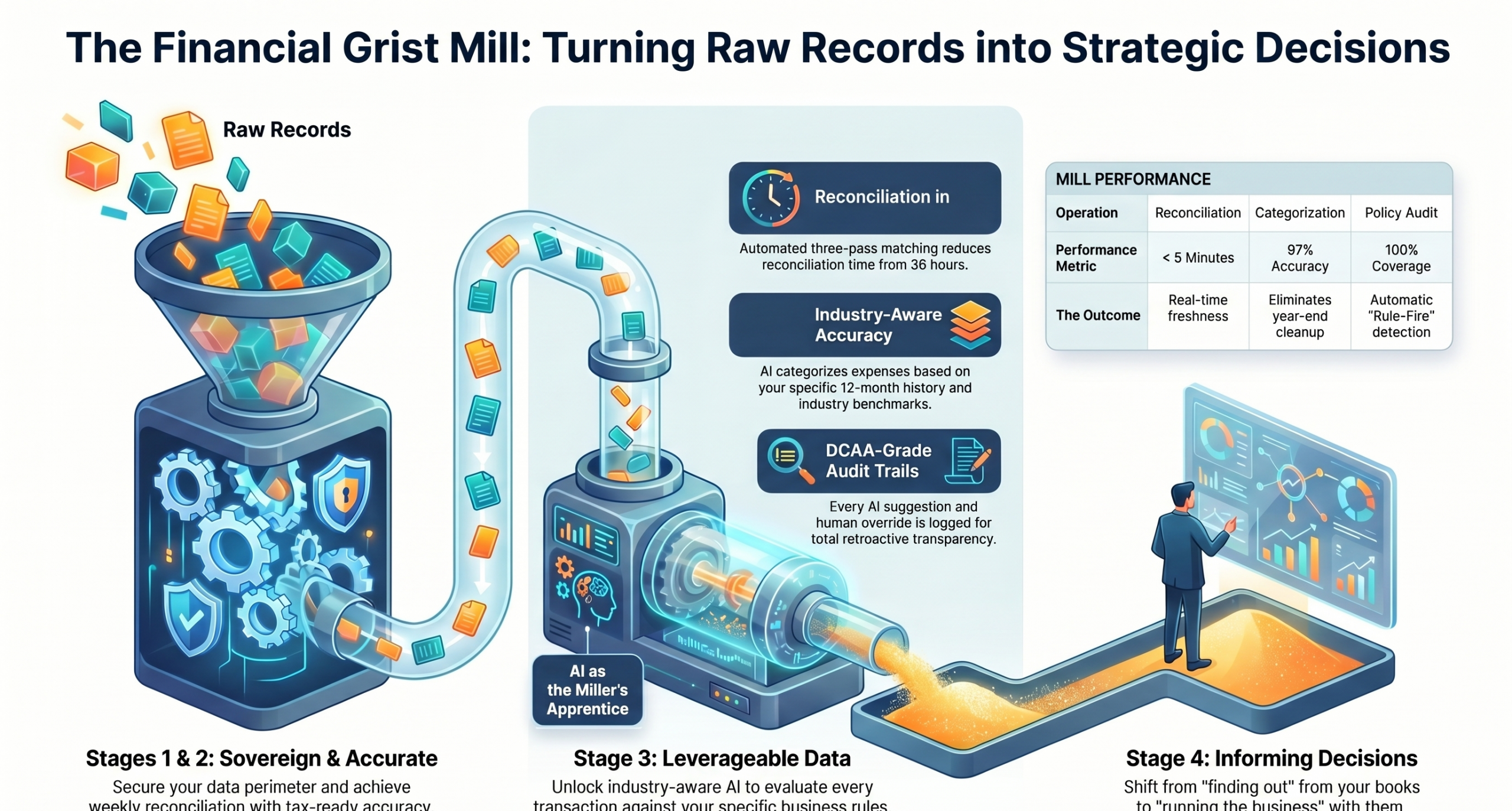
The Financial Grist Mill: raw records enter as grain; the mill (reconciliation, industry-aware classification, audit trails) turns them into clean, defensible books; the four maturity stages run left to right from Sovereign to Informing Decisions.
Raw transactions come in like grain. The four-stage flow — sovereign, accurate, leverageable, informing decisions — is the milling. The classifier, the policy engine, the reconciliation, the audit log, the retrieval layer, the agent runtime: each is part of the mill. The output of the mill is flour — clean, defensible, leverageable financial data the CFO and the owner can trust. Flour is necessary, but flour is not the outcome. Flour gets carried over to the baker — to the CFO Operating System — where it becomes the actual things owners hire a CFO to deliver: a pricing call you can defend, a customer fired with the numbers to back it, a growth bet sized against a 13-week cash forecast, a payroll decision against utilization actuals, a year-end conversation that opens with strategy instead of cleanup. That is the bread, the cake, the cookies. Take the mill away and AI has nothing to grind. Take the baker away and flour piles up in the pantry.
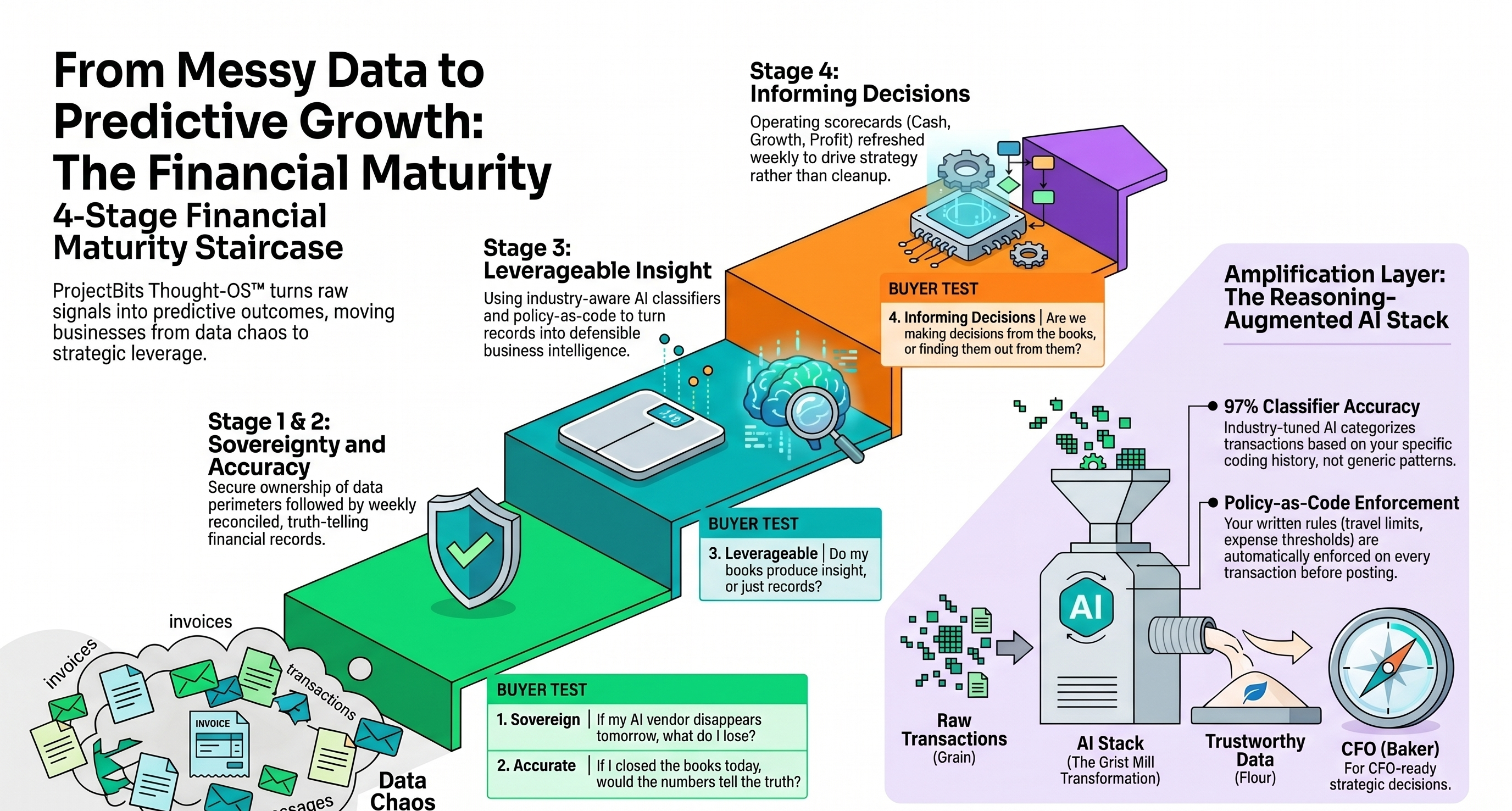
Financial Maturity 4-Stage Staircase composite showing all four stages, buyer tests, amplification layer, and the grist-mill-to-CFO flow in one frame.
Many "AI bookkeeping" products ship you the oven and forget the mill. They categorize what’s already in QBO, hallucinate when they don’t know or understand, and produce little the operator can defend at year-end. Tax Ready Bookkeeping runs the mill. The AI Stack is what makes the mill worth running. The next book — The CFO Operating System — is the baker, and the bread is the decisions that grow the business.
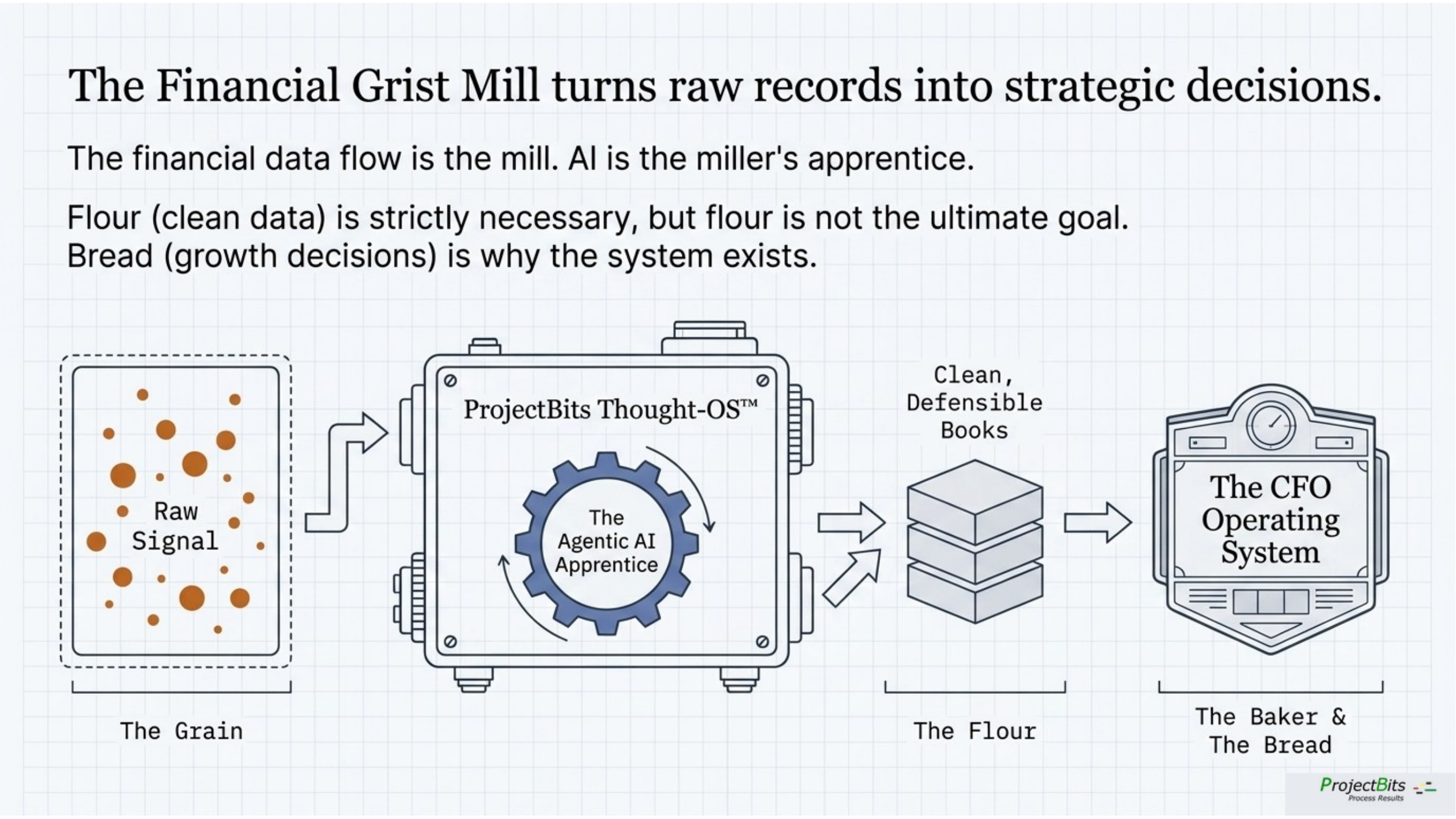
The Financial Grist Mill: Grain → ProjectBits Thought-OS / Agentic AI Apprentice → Clean Defensible Books (Flour) → CFO Operating System (Baker & Bread).
How the mill was built — and how it gets better. We built it through intentional design — every component evaluated against named alternatives, every choice tied to a business outcome, every trade-off acknowledged out loud. And we refine it through iterative real-world improvement — the classifier got to 97% by being measured and re-tested; reconciliation got from 36 hours to under 5 minutes by being used and adjusted; the 9-category benchmark is scored monthly because monthly is what catches drift. The design wasn’t theoretical; it was the starting point. Every engagement teaches us something the design didn’t anticipate, and the mill takes those lessons and improves. That’s the difference between a system that was built once and one that keeps learning and improving how it is working.
We hold ourselves to the same discipline we deliver. The infrastructure that runs the mill is benchmarked against a public 7-layer production-grade agentic-AI framework — the same kind of structured maturity model we apply to your books. As of March 2026 it scores 61% production-grade overall, up from 48% the prior assessment. The 13-point lift came from two specific deployments (LLM observability via LangFuse, load testing via k6) — measured the gap, shipped the fix, re-scored. We don’t ask clients to trust a system we wouldn’t grade ourselves on; the score moves because we measure it.
The four-stage thesis
Every small business with QuickBooks captures and records financial data. Almost none of it is leverageable — it sits in QBO as unreviewed or posted records, not signals. The path from records to decisions runs through four stages, each a prerequisite for the next.
| # | Stage | What it means | What fails without it | The buyer test |
|---|---|---|---|---|
| 1 | Sovereign | You control your data and your processing. Your perimeter, your audit trail, portable on demand. Sovereignty is a contractual and architectural property — not a question of where the box lives. | Your AI vendor’s pricing, policies, or availability dictates your finance function. | "If my AI vendor disappears tomorrow, what do I lose?" |
| 2 | Accurate | Reconciled weekly, dimensionally classified (Class / Location / Project), documents linked, 9-category benchmark scored monthly. | AI on dirty data is worse than no AI. Year-end is archaeology. | "If I closed the books today, would the numbers tell the truth?" |
| 3 | Leverageable | Industry-aware classifier suggests categories; reconciliation engine matches accounts in three passes; policy engine evaluates every transaction against your written rules; audit log captures every AI suggestion and every human override. | AI is a parlor trick — interesting demos, no operational work, no conviction at year-end. | "Do my books produce insight, or just records?" |
| 4 | Informing decisions | A six-category operating scorecard — Cash · Growth · Delivery · Profitability · Process · Recommendations — refreshed weekly. 13-week cash forecast, scenario models, customer-profitability ranking, industry-benchmarked KPIs. Fractional CFO arrives to data they can trust. | Advisory engagements stall in cleanup. You find things out from the books instead of running the business with them. | "Are we making decisions from the books, or finding them out from them?" |
Most small businesses are stuck between Sovereign and Accurate. Some reach Leverageable but the data is too noisy for AI to add value. Almost none reach Informing decisions — because their books were never built for it.
Tax Ready Bookkeeping is the practice that gets the data to Stage 2. The AI Stack is what unlocks Stage 3. The combination is what makes Stage 4 — a traditional or fractional CFO who advises rather than cleans — possible at all.
[The standalone Staircase visual is reserved for /method/ and /insights/ai-readiness/; on this page the composite at the top already carries the four-stage view.]
Why AI alone fails — and what fixes it
Most small-business owners hearing "AI in the books" picture a black box that categorizes transactions. That product exists. It is only a part of what we provide, and it is not why customers should care.
Three failure modes when AI runs the books alone:
- Hallucination on numbers or events it doesn’t know or fully understand. Generic AI categorizes "Microsoft 365" as "software" and stops. It doesn’t know that an MSP has tiered SaaS — Datto, ConnectWise, M365, Webroot — that need to land in different accounts to make customer profitability legible.
- No memory across time. A categorization that was right in March drifts in October because the AI doesn’t remember what your team bookkeeper decided. By year-end the same vendor lives in three accounts.
- No audit trail. When DCAA, your tax preparer, or your CPA asks "why is this here?" — and you can’t reconstruct what the AI did six months ago — you have an audit problem. This is non-negotiable for anyone with compliance weight requirements, most of us.
What fixes it: four operations running together, grounded in curated retrieval.
| Operation | Built today | What it adds |
|---|---|---|
| Categorize | Embedding + kNN classifier (mxbai-embed-large, k=3), benchmarked at 97% accuracy on the categories your business actually uses. Industry-tuned. | The AI suggests against your 12-month coding history, not its training memory. |
| Reconcile | qbo-reconciliation engine — three-pass matching (exact, date-tolerant, fuzzy) across bank ↔ QBO ↔ payment processor. | "From 36 hours to under 5 minutes" is a measurement, not a marketing claim. |
| Evaluate | Open Policy Agent (OPA)/Rego – a compliance language — 10 production policies (FAR/DCAA, expenses, capitalization, month-end, vendor approval). Demonstrated live in the Policy Compiler video. | Your written rules run automatically on every transaction, before anything posts. |
| Audit | Decision log — every AI suggestion, every human override, every policy verdict, queryable by date / account / vendor. | Reconstruct any decision retroactively. DCAA-grade. |
From Hours to Minutes: the manual line-by-line reconciliation (≈36 hours) versus the QBO reconciliation engine — AI-powered OCR, multi-source import, and three-pass matching — under 5 minutes at 99% time reduction.
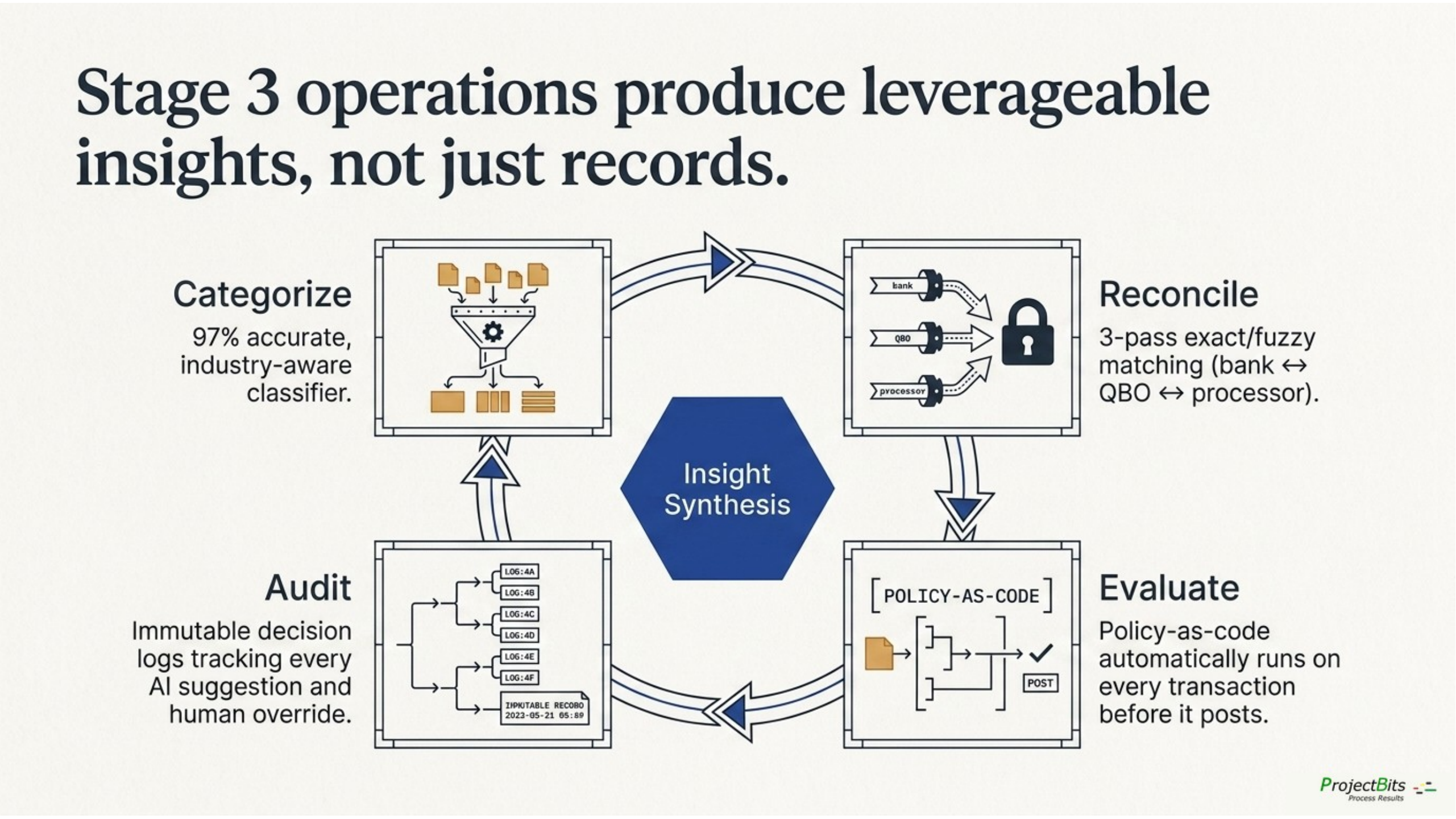
the four operations arranged around Insight Synthesis: Categorize / Reconcile / Audit / Evaluate.
Run those four over time, and a fifth thing emerges: insight. Not "AI being clever." Patterns. The classifier disagrees with current coding 6% of the time, and the disagreements cluster around two vendors. Reconciliation is fresh on 23 of 24 accounts; one account has been stale for 14 days. Per-diem rule fired 11 times this month vs a 2–3 baseline. Telecom spend is 3× the MSP-peer median.
Those findings are what a CFO opens first. They emerge from the operations running, not from a separate "anomaly detection" product.
The principle: AI for interpretation, code for structured and repeatable execution, humans to informa and approve decisions the policy says require a human. The model proposes; the predefined process evaluates and produces findings and recommendations; the policy decides whether the entry auto-posts (low-risk, matching the rules) or routes to a human review queue (anything outside the rules). By design, your written policy is the authoritative source of truth for what posts how — not the vendor’s defaults, not the model’s confidence, not anyone’s hunch.
Industry-aware by design
Generic bookkeeping even with some AI enhanement, treats every business the same. Tax Ready Bookkeeping doesn’t. The integrated data flows, chart of accounts, classifier training, policy parameterization, and KPI benchmarks are configured for your vertical at onboarding. The vertical strategy lives in three tiers.
Professional Services on QBO — primary
The umbrella that covers consulting practices, advisory firms, fractional CFO / CTO shops, agencies, boutique professional firms, and MSPs as a tech-services flavor of professional services. The three questions are the same; the operational stack underneath them differs.
The three questions that define a professional services firm’s books:
- Where is time going? — Time-tracking or PSA tickets → billable units per engagement per client
- What does each engagement cost? — Loaded labor + engagement expenses + non-billable overhead allocation
- Which clients actually make money? — Engagement revenue − billable cost − non-billable hours − overhead = client profitability
The system answers all three by integrating the operational source (PSA, Toggl / Harvest, native time-tracking, project management) with QBO. Different operational stack per sub-flavor; same three questions, same architecture.
Consulting / advisory / fractional / agency
| Anomaly the system surfaces | Why it matters |
|---|---|
| "Project Larson Industries: 64% billable, 36% non-billable. Your project-typical baseline is 78 / 22. Margin leakage worth a conversation." | Fixed-fee project drifting from estimate; PM needs to reset scope or rate. |
| "Retainer Greenfield Co — 40 hours each of last 4 months. This month: 12 hours. Client gone quiet, or hours not entered." | Retention risk surfaced before invoicing. |
| "Subcontractor labor coded to 5400 (Cost of Services) but missing 1099 vendor flag. 12 transactions in May." | 1099 obligation visible in real time, not next January. |
MSP / IT services — sub-flavor, PSA-driven
| Anomaly the system surfaces | Why it matters |
|---|---|
| "Customer Acme: MRR $2,400, but tickets-to-resolve hit 47 hours this month — 3× your portfolio average. Customer profitability: −$180. They’re costing you money." | The conversation about firing or repricing this customer starts with a number, not a hunch. |
| "Tooling allocation for Datto bumped 18% across 3 customers; one of them isn’t on the plan you upgraded. Allocation drift." | Margin leakage caught the month it happens, not at year-end. |
| "Verizon Wireless: $4,200 — 3.0× MSP-typical telecom spend." | Right account, wrong size. Plan changed and nobody updated the budget. |
Trades / Field Service on FSM + QBO — secondary
Service businesses running on operation products like ServiceTitan, Housecall Pro, Jobber, or similar. Crew-based, owner-operator or small GM team. High job volume, $1M–$10M revenue. Busy and broke at the same time. Job costing lives in a spreadsheet or doesn’t exist because consitant coding is difficult; change orders disappear into the books; bonding and lending conversations are painful because the financials don’t hold up.
The system surfaces job-by-job profitability the same way it surfaces engagement profitability for professional services — different operational source (FSM not PSA), same architectural pattern.
Financial Services and Real Estate — tail
Small wealth-management firms, RIAs, fractional CFO practices serving non-VC-backed firms, and real-estate operations bookkeeping — property managers and holding companies in operations mode (not 1031 / cost-seg specialty). Compliance pressure higher than peers; books need to stand up to a regulator, lender, or partner-in-residence at any moment.
The system surfaces the same three questions adapted to engagement type — AUM-fee revenue per client, advisor labor per client, compliance-overhead allocation; or property revenue, operating expenses, asset-level depreciation tracking.
Cross-vertical — the policy-stage signal
The fit signal that runs through all three tiers, independent of vertical: the owner has written operational policies as the team grew — travel limits, expense thresholds, approval rules, billing standards — and is starting to wonder if those policies are being followed. The Tax Ready Assessment locates the firm on the Financial Maturity Staircase; Tax Ready Bookkeeping is the service that turns those written policies into rules every transaction is evaluated against. Past just-ask-me, into write-it-down, looking for enforce-it-mechanically.
The same architecture serves all three tiers — different account templates, different classifier patterns, different policy parameters. The system "knows the difference."
Why niche focus is the right strategy. A generalist bookkeeper learning a new vertical has to rebuild context — the chart of accounts, the operational system on the other side of the integration, the policy questions an owner in that industry actually asks, the benchmarks that mean something to them. A specialist starts with that context already built. The conversation with the owner sounds different from the first call: "your tooling spend on Datto across these three customers is drifting, here’s what that usually means" lands differently than "your software expense looks high, you might want to look at it." Niche focus is what turns a bookkeeping engagement into an advisory relationship — and the outcome an owner remembers is the relationship, not the close.
The curated retrieval layer that knows your business
The reason the AI can be trusted with your books is that it doesn’t answer from training memory. It answers from a curated retrieval layer that you and ProjectBits control — your data, your processing, your audit trail, sovereign by design.
Control and sovereignty are the principle. Deployment is the menu. "Dedicated infrastructure" means dedicated to your engagement — not pooled with anyone else’s, not training anyone’s model — and there are several legitimate ways to deliver it, each with the same control guarantee:
| Deployment mode | What it looks like | When it fits |
|---|---|---|
| Platform-as-a-Service (PaaS) tenancy | ChromaDB, the agent runtime, and the workflow rail running in a dedicated tenancy on AWS / Azure / GCP / similar — contractually isolated, your data, your encryption keys where supported. | The dominant modern mode. Right when you want the operational economics of the cloud without pooled-tenant exposure. |
| Private cloud you own | Same stack running in your own cloud account, billed to you, administered jointly. | Right when your security or compliance team requires the perimeter to be inside your billing relationship. |
| On-premises | Same stack running on your hardware, in your data center. | Right when regulatory or contractual obligations require physical custody. |
| ProjectBits-hosted | Same stack on infrastructure ProjectBits operates, with the same contractual isolation as a SaaS arrangement that names your data is never used to train any model. | Right when you want the simplicity of a managed service and the control of a dedicated tenant. |
| Mixed | The stack split across modes — for example, the agent runtime in your PaaS tenancy, the retrieval layer ProjectBits-hosted, the workflow rail on your premises. | Most engagements end up here. The architecture supports it by design. |
The word that ties them together is dedicated to your engagement. ChromaDB is the retrieval engine in every mode; what changes is whose perimeter it runs in. Curation — the editorial work of canonical-source designation, supersession, time-decay weighting — is the same work regardless. Curation is what makes retrieval honest. Control and sovereignty are what make it yours.
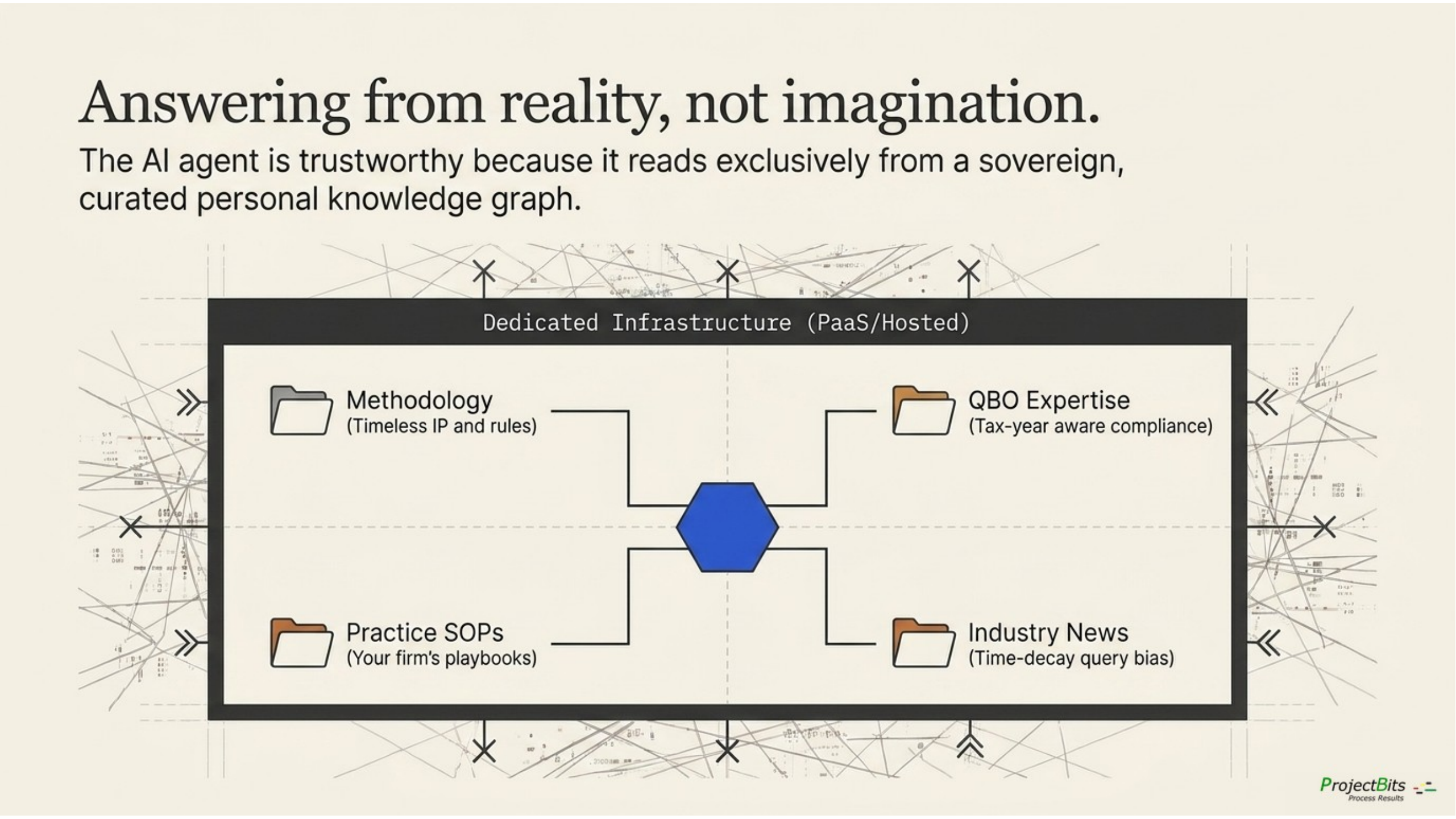
Dedicated PaaS/Hosted infrastructure with four retrieval collections (Methodology / QBO Expertise / Practice SOPs / Industry News) fanning from a central hub.
To make this concrete — here’s what runs in our lab. Our practice runs the ProjectBits-hosted deployment mode on our own infrastructure, because we are the practitioner-customer of our own architecture and we use the lab as both a working environment and a reference implementation. The retrieval layer is ChromaDB on a dedicated RAG host (one box, one purpose). The agent runtime is OpenClaw on a small Kubernetes cluster. The workflow rail is n8n, also on Kubernetes. Local LLM inference runs on a Tesla P40 for sensitive workloads; frontier models (Claude, Gemini, OpenAI, Perplexity) are reached over named API contracts with no-training clauses. PostgreSQL holds the session history and structured memory. Everything is wrapped in Cloudflare Zero Trust at the perimeter and benchmarked monthly against a public 7-layer production-grade framework. The 61% score we cite earlier in this whitepaper is this lab’s score. When you ask "how does this actually look in production?" — the answer is: it looks like our lab, sized for your business, deployed in the mode that fits your control requirements.
Existing — the personal knowledge graph (152,609 chunks across 8 collections). Books read, research sessions, methodology development conversations, AI agent runs, curated bookmarks. This is the substrate — it answers methodology and practice questions cleanly (e.g., "How should I price fractional CFO services?" pulls from book insights, prior sessions, and Kindle reading). Personal knowledge, biographical in shape.
Under active build — four topical collections that ground operational AI:
| Collection | What it holds | Time-aware? | Why it matters |
|---|---|---|---|
| projectbits_methodology | The 9-category benchmark, Financial Maturity Staircase, policy-to-workflow rules, audit-trail design, brand voice. ProjectBits IP. | No — timeless | The AI answers methodology questions in your methodology, not generic bookkeeping. |
| qbo_expertise | IRS publications (535, 583, 463), ProAdvisor practice notes, QBO API reference, vertical-specific bookkeeping research. Authority-tagged. | Tax-year-tagged for items that decay | Conflicts between official sources and community noise resolve toward authority. Tax-year-aware questions get tax-year-aware answers. |
| projectbits_practice | SOPs, runbooks, sales process, engagement letters, onboarding checklists, pricing tiers, anonymized lessons learned. | No | The bookkeeper’s question gets a ProjectBits answer, not a generic one. |
| industry_news | IRS news releases, Intuit announcements, MSP / vertical trade press, EOS publications, regulatory changes. RSS-polled, email-forwarded, bookmarklet-ingested. | Yes — time-decay query bias | This week’s IRS Rev. Proc. surfaces in this week’s bookkeeping decisions. Old guidance gets demoted. |
The four collections close the loop on Stage 3. They’re the difference between "AI categorized your expenses" and "the IRS issued a per-diem update last week and your books haven’t caught up — here are the two transactions that need re-evaluation."
Why this matters competitively. Any generic AI bookkeeping competitor would have to (a) build four curated collections, (b) integrate time-decay logic, (c) train per vertical, (d) connect a policy engine, (e) build the ingest pipelines, and (f) earn enough trust to be allowed inside customer perimeters. This is years of work. We did it.
Where humans interact with the system
Humans interact with the system across several surfaces — not one. We chose each surface for what it does well, evaluated against the specific interaction it serves. The discipline matters: we’re not collecting tools, and we’re not pretending one platform answers every need. We incorporate a tool where its strengths line up with a business outcome, and we accept its trade-offs explicitly.
| Interaction | Right surface | Why we chose it |
|---|---|---|
| Daily ledger work, customer-facing reports, system-of-record | QuickBooks Online | What your CPA expects, what your auditor reads, what AP / AR runs against. We don’t replace it; we make it more reliable. |
| Where the work actually happens — tickets, time, jobs, projects, properties, units | Your industry-specific operational system — PSA for MSPs (ConnectWise / HaloPSA / SuperOps / Autotask); time tracking for consulting (Toggl / Harvest); FSM for trades (ServiceTitan / Housecall Pro); property management for real estate (Buildium / AppFolio) — with bidirectional integration into the data flow | This is where billable activity originates — long before it shows up in QBO. Cherry Bekaert’s professional-services CFO research found that 72% of firms cite data integration as a top pain point, with reporting at 63% and forecasting at 49%. Integrating these systems is what lets us answer the three questions the books can’t answer alone. Without this surface, the system only knows what was invoiced; with it, the system knows what was worked — and customer profitability, utilization, and job-cost variance become real numbers the bookkeeper and CFO can defend. |
| Recurring workflows, scheduled jobs, multi-step orchestration | n8n | Deterministic, retriable, auditable. Every step logs to a queue you can rerun. The deterministic rail at Tier 8 — and the bridge between QBO, the operational systems, the AI stack, and the dashboards. |
| Conversational review, exception handling, advisory prep, judgment-heavy interactions | OpenClaw (self-hosted agent runtime) | Per-client agent isolation, packaged specialist behaviors, paired-device input for receipt capture inside your perimeter, overnight pattern consolidation that produces a narrative briefing of what’s worth a human’s time. |
| KPI snapshots, scorecard trends, dashboard views | Web dashboard / Grafana | Quick visual answers for "where are we?" — without opening a conversation. |
| Approvals on the go | Email / Teams / Slack | Approvals happen where the bookkeeper and owner already are. The system meets them there; it doesn’t make them come to a new app. |
Why OpenClaw specifically — and what we accepted in return
OpenClaw earns its place in the stack because four of its capabilities directly serve outcomes nothing else delivers as cleanly. We named the trade-offs going in.
The capabilities that fit the work:
- A dedicated agent per client. Each engagement runs its own agent with isolated memory, persona, and workspace. Sovereignty is enforced by the runtime, not by promises. Your agent doesn’t learn from another client’s books.
- Packaged specialist behaviors. Categorize this expense, build the weekly scorecard, flag anomalies for close, generate the policy violation report. Consistent results across sessions; the agent doesn’t have to be re-prompted for each task.
- Paired-device input. Phone-camera receipt capture, screen capture for QBO observation, image processing — handled inside your perimeter. The transaction journey can start with a photo without sending it to a third-party cloud OCR pipeline.
- Overnight pattern consolidation. Background memory processing in three phases modeled on human sleep cycles. While your bookkeeper sleeps, the agent stages recent signals, promotes durable patterns to long-term memory, and extracts themes — producing a narrative diary of what’s worth a conversation. Your fractional CFO opens the diary at the start of the week and begins with themes the agent already noticed.
Trade-offs we accepted:
- Activation curve. Overnight consolidation is opt-in and disabled by default; activating it is service-rollout work. Worth it for the fractional CFO use case; we’re not pretending it’s free.
- Integration footprint. n8n has a wider pre-built integration library. OpenClaw shines on conversational and judgment work but isn’t a substitute for n8n’s deterministic orchestration. We use both, deliberately.
- Operational overhead. It’s another platform to monitor, back up, and version. We accepted that because the per-client agent model and overnight diary capability aren’t available elsewhere — and the outcome they unlock (advisory-ready data on Monday morning) justifies the cost.
The discipline: every component — OpenClaw, n8n, ChromaDB, OPA, the classifier, the reconciliation engine — earns its place because of a measurable business outcome. Tools that don’t deliver outcomes get cut. We evaluate; we don’t collect.
Five questions we hear owners actually ask
The v1.1 whitepaper opened this section with "Five Finance Fears" — defensive framing about what could go wrong. Owners ask different questions. The questions worth answering are about elevation, not protection. Here are the five.
| Question | Honest answer |
|---|---|
| Will this raise my game — give me a clearer view of my financial position and help me make better decisions? | Yes. That’s the entire point. Books that close on time. Reconciliations that match. Categorizations that hold up across the year. KPIs that mean something for your industry. You go from finding things out from your books to running the business with them. |
| Should I learn some of this myself, or is it all my bookkeeper’s job? | Learn some. Not necessarily the technical layer if not your interest — the AI’s behavior, your policies, what your benchmarks mean for your industry. ProjectBits is your sherpa for the climb; you still need to prepare for the ascent. The owners who get the most out of the system are the ones who understand what it can answer and shape it toward the questions their business actually faces. |
| What if the AI is wrong? | Posting takes place per the policy you write. Routine, low-risk transactions matching your rules can auto-post; anything outside those rules routes to a human review queue, by design. If a suggestion is wrong, it’s wrong in the queue you review — not in your books. Your policy decides where the line is, not the vendor. |
| How do I know I’m getting real value, not just hype? | Two scorecards, both visible. Yours: the 9-category benchmark scored monthly — you watch the number move. Ours: the infrastructure your engagement runs on is itself scored against a 7-layer production-grade framework (currently 61%, up from 48%). We hold ourselves to the same kind of public maturity scorecard we hold your books to. The first industry-aware finding that changes a decision — you’ll know it when you see it. The hours your bookkeeper gets back on reconciliation. If those signals don’t show up, the engagement isn’t working — and we’ll tell you that, not bill you for another quarter. |
| What does success look like 90 days in? | Three concrete signals. The benchmark score has moved. The system has surfaced findings that prompted real conversations — about a customer’s profitability, a vendor pattern, a policy gap. By month four, the conversation with your fractional CFO is about strategy, not data cleanup. That’s the bridge from Stage 3 to Stage 4. |
The technical analogies and the deeper sovereignty narrative live in the appendix where CTOs and CFOs read them.
Receipts — the discipline applied to the practice
The disciplines this paper describes are not theoretical for ProjectBits. They are the practice we run on the practice. The marketing strategy, methodology library, session history, client correspondence, and reference material that drive day-to-day decisions live in a curated retrieval system we built and maintain — the same architecture pattern this paper recommends, sized for a small consulting practice.
Concretely, what that looks like today (mid-May 2026) — published as a living, searchable documentation site via MkDocs alongside the underlying retrieval store:
A canonical-source-designated methodology corpus. Canonical source is the records-management term for the one document on a topic that is the authoritative master version — every other document on the same topic is explicitly marked as superseded. Six governing documents fit that test here — positioning, methodology, onboarding playbook, voice, brand kit, and the umbrella methodology page — each with explicit status (canonical / living / locked), supersession metadata, and review cadence. Older PDF versions of the cornerstone marketing document are explicitly marked as superseded and excluded from retrieval. Multiple sources of truth produce contradictory answers; we eliminated ours.
A multi-format intake pipeline feeding ten retrieval collections. Markdown, PDFs, EPUBs (technical books), meeting transcripts, web articles, AI-conversation exports, and bookmarked external material flow into a vector store carrying roughly 195,000 indexed chunks. Working sessions, conversation history, ingested books, industry news with time-decay weighting, and curated external reference material each get their own collection.
A session-history archive that compounds. Every working session is captured to a PostgreSQL log with topic, summary, and keyword indexes; 304 sessions logged to date, transcripts ingested with provenance metadata. New work begins by querying prior work. The point at which this stopped being a backup system and started being institutional memory was the point at which retrieval became faster than the colleague-asking it replaced.
A live entity-resolution layer. Contacts in the CRM, leads from outreach platforms, meeting participants, and email senders are reconciled to single canonical identities — the SMB-appropriate version of master data management, not an enterprise MDM rollout. A cross-system query for "everything we have on this person or company" returns one answer, not three.
A canonical service registry for the practice’s own infrastructure. What runs where, with what credentials, on what health endpoint, is stored in one queryable place — applied to the firm’s own operations, not just client engagements. The discipline doesn’t stop at the books.
What’s still incomplete — and we say so. The question-capture loop we designed for surfacing, scoring, and feeding back the questions that drive corpus value exists as an architecture specification. Meeting-transcript intake is live; the canonicalization, scoring, and gap-tracking layers are design specs, not running code. We are working through them the same way we would work a client through them — sequenced, measured, no leaping ahead. The retrieval store carries decades of accumulated correspondence and reference material, but the formal audit — canonical-source designation and metadata schema applied retroactively to legacy content — is an ongoing multi-month effort. The audit doesn’t get done; it gets maintained.
Why we show this. The architecture in this paper isn’t a sales pitch built from a whiteboard. It is the working specification of the system we are using to run our practice. Anything we recommend, we have been operating against ourselves — long enough to know which parts hurt and where the corners get cut under deadline pressure. When we walk a client through the assessment, the diagnostic, or the maturity ladder, we are walking them through territory we have already crossed.

receipts panel: 36 hrs → 5 min reconciliation; 97% classifier; 73 → 9 days invoice processing; 48% → 61% production-grade maturity.
What this unlocks — the bridge to the CFO Operating System
Most fractional CFO engagements stall in the first 60 days. The CFO arrives, looks at the books, and finds out they’re three months behind. Reconciliations are stale. Categorizations are inconsistent. Policies live in a binder. The first 30 days become cleanup. The client’s reaction: "I hoped for more value."
The Tax Ready + AI Stack combination changes the first month entirely. The CFO arrives to a system that is already starting to produce its own findings and opportunities:
- Industry-benchmarked KPIs — not "your expenses are up" but "your tooling spend is 18% above MSP-peer median, driven by these three vendors."
- Classifier-flagged disagreements — 14 transactions where the categorization pattern says one thing and the current coding says another. Each one a specific, reviewable item.
- Reconciliation freshness map — which feeds are reliable, which need attention, which have been stale long enough to hide problems.
- Policy fire trends — per-diem rule fired 11 times in May vs 2–3 baseline. Travel pattern shifted; worth a structural conversation, not a one-off cleanup.
- Customer profitability ranking — which clients actually make money, with the numbers to defend the call.
The CFO’s first conversation with the owner isn’t "let me look at your books." It’s "the system flagged these three things — let’s start with which one matters most to your business this quarter."
The economics, anchored in market data. Pilot reports the open-market range for fractional CFO services as $3,000 to $12,000 per month, with $5,000 to $8,000 as the typical early- to mid-stage average; Anders’ average virtual CFO engagement runs $78,000 per year. Higher costs are explicitly attributed to messy books, frequent support, and manual systems — i.e., to time the CFO has to spend on cleanup instead of advisory. Dark Horse anchors the entry point with a paid CFO Assessment starting at $5,000 that produces a CFO Roadmap. The combination of clean Stage 3 data plus a productized advisory layer makes a $7K–$10K / month engagement defensible because the CFO is doing $7K–$10K of advisory — not $3K of advisory and $5K of cleanup. The buyer is paying for the work the system can’t do, not for the work the system already did.
The named offer — ProjectBits CFO Operating System
The next book’s spine is a four-package productized service — provisionally ProjectBits CFO Operating System — built for consulting and professional service firms ($2M+ revenue is the market-typical entry threshold per Anders / FocusCFO). The four packages mirror the chapter structure:
| Package | What it is | Cadence | Benchmark anchor |
|---|---|---|---|
| 1. Operating System Diagnostic | Paid entry-point engagement: Operating System Readiness Score, financial data quality score, KPI dictionary, CFO dashboard blueprint, core process gap list, 90-day implementation roadmap. | One-time project. | Dark Horse CFO Assessment ($5K+); Cherry Bekaert modernization framing. |
| 2. CFO Control Tower | Recurring fixed-fee subscription: monthly close + management reporting, weekly KPI scorecard refresh, cash forecast, project / client profitability, utilization / realization, pipeline-to-capacity, monthly CFO operating review. | Weekly + monthly. | Pilot $5K–$8K typical; Lucrum $1,599 SMB anchor; The CFO Project’s productized model. |
| 3. Finance Process Buildout | Project-based implementation accelerators: QuickBooks cleanup, CoA redesign for professional services, PSA-to-QBO workflow, time-and-billing redesign, WIP / AR automation, dashboard buildout. Scoped separately from advisory so the CFO subscription doesn’t become unlimited systems work. | Project sprint. | Cherry Bekaert CRM → PSA → ERP → BI flow framing. |
| 4. Quarterly Growth & Recommendations | Add-on for firms self-implementing a Business Operating System: convert Rocks to financial measurables, capacity / cash / budget impact analysis, financial accountability for priorities. |
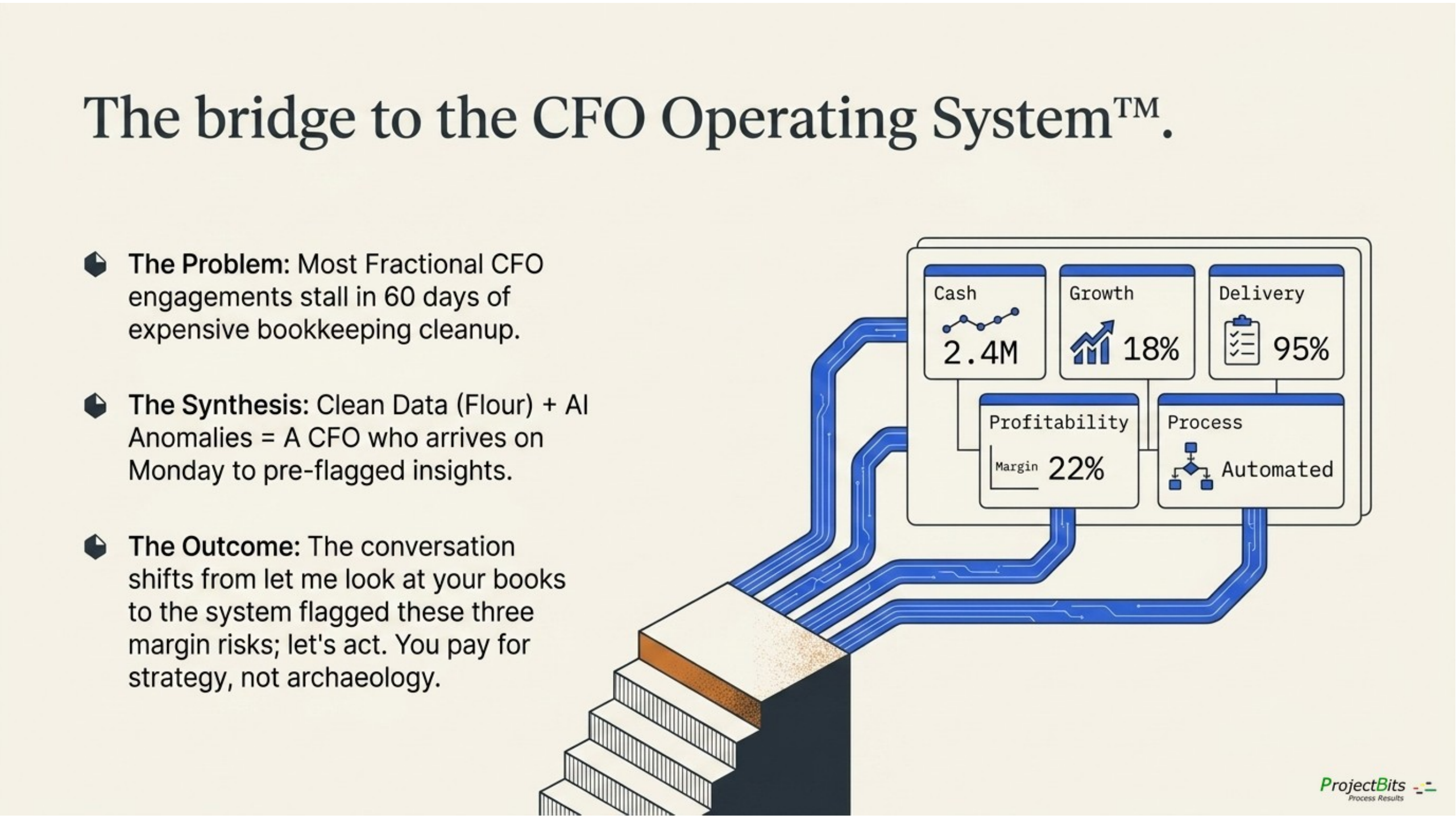
the bridge from Stage 3 to Stage 4: a populated six-category operating scorecard (Cash / Growth / Delivery / Profitability / Process / Recommendations) arriving ready for the CFO conversation.
Said in the metaphor: This whitepaper describes the mill. The next book is the baker. The bread is the decisions that grow the business.
Where to start
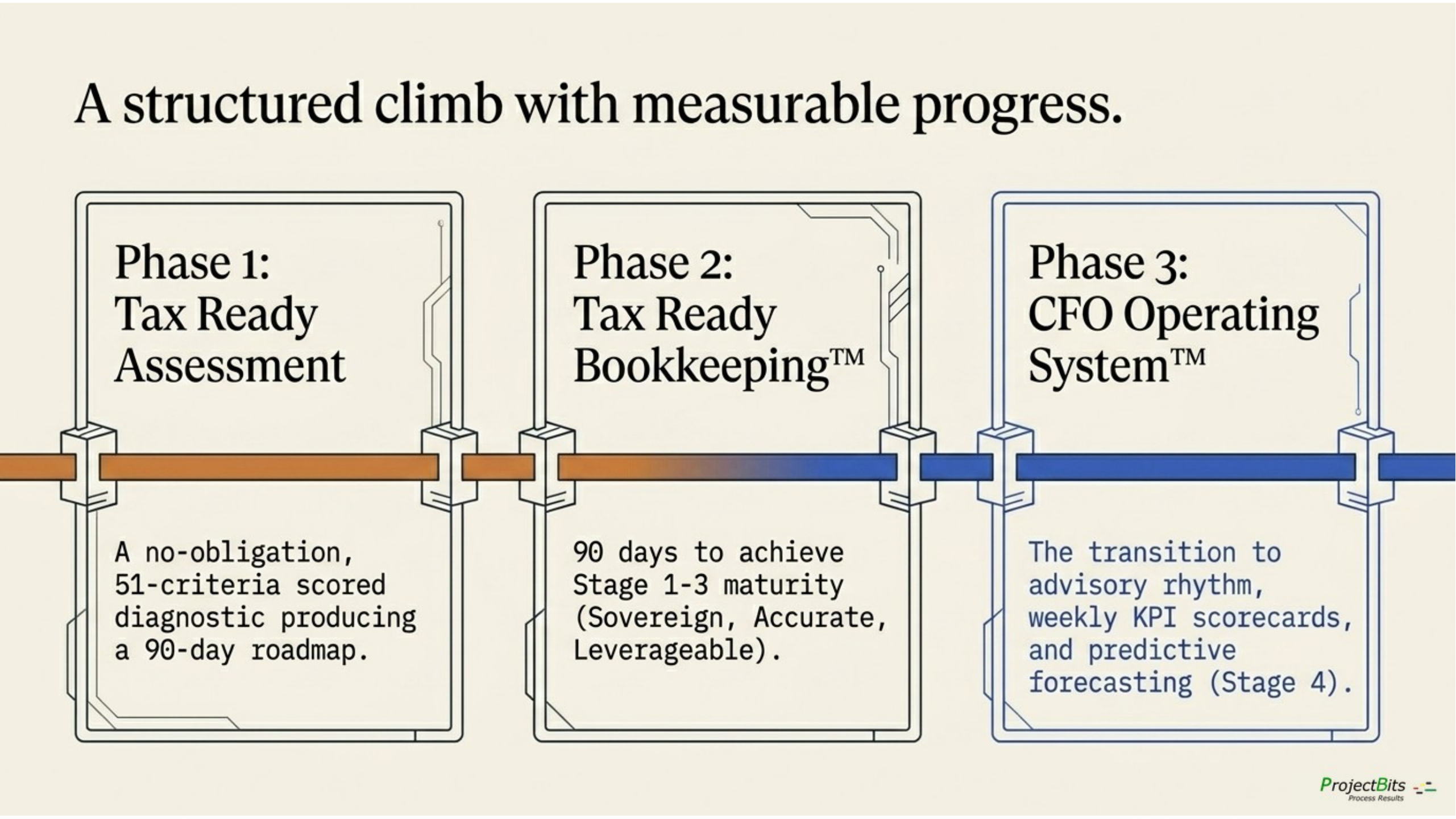
the three-phase engagement arc: Phase 1 Tax Ready Assessment, Phase 2 Tax Ready Bookkeeping, Phase 3 CFO Operating System. The trilogy unifier — same image appears on /insights/ai-readiness/ and /method/.
This whitepaper makes a case. The case has an obvious next step: a real measurement of where your business actually stands on the Financial Maturity Staircase. The disciplines described above are scale-independent — the SMB-appropriate version is reachable inside a year of focused work for most firms — but the path is sequenced, and skipping rungs doesn’t work.
The entry path is the Tax Ready Assessment — a no-obligation scored diagnostic across 51 criteria in 9 categories. It places your business on the Financial Maturity Staircase, surfaces the specific gaps that matter most, and produces a 90-day roadmap. Yours to keep whether or not you engage further; the diagnostic is real on its own.
For firms where bookkeeping isn’t the obvious starting point — for example, when the data integration problem is louder than the records problem — a 20-minute conversation reaches the same diagnosis through different questions. The same methodology applies; the entry point shifts.
Take the No-Obligation Assessment · Schedule 20 Min with Don
Appendix — The 8-Tier Stack as proof
The 8 Tiers are real. They earn their place by delivering the four guarantees behind the four-stage thesis: sovereignty, auditability, model independence, and operational reliability. The same discipline from §5 applies here: each tier was chosen against named alternatives, with the trade-offs evaluated.
| Tier | What it is | Stage / guarantee | Why this and not the alternative |
|---|---|---|---|
| 1 | LLM — Claude / Sonnet, Gemini, Perplexity, OpenAI cloud + Ollama local on Tesla P40 | Stage 3 / Model independence | Alternative considered: single-vendor cloud (e.g., OpenAI-only). Single-vendor lock-in risks pricing, policy, and availability shocks. Bidirectional fallback (cloud ↔ local) eliminates the single point of failure and lets us match workload to model — frontier for hard reasoning, local for sensitive data. |
| 2 | Context — finite per-call window, smart retrieval, redaction at the boundary | Stage 3 / Operational reliability | Alternative considered: stuff everything into the prompt. That works in demos; production breaks on cost and signal-to-noise. A bounded context with smart retrieval is what makes the RAG layer worth running at all. |
| 3 | RAG — ChromaDB on dedicated RAG host (prag) with curated topical collections + personal knowledge graph | Stage 3 / Sovereignty + accuracy | Alternatives considered: pgvector inside the main DB; no RAG (let the LLM use training memory). No-RAG fails because training memory is generic and stale. Pgvector co-located with operational data couples concerns. A dedicated RAG host with ChromaDB lets us scale the knowledge layer independently and keep its blast radius contained. |
| 4 | MCP / Tools — Model Context Protocol on k3s, Cloudflare Zero Trust tunnel | Stage 3 / Auditability | Alternatives considered: ad-hoc REST calls, hardcoded tool descriptors, OpenAI function-calling format. MCP is an open protocol — the same tool server works across LLM vendors. Per-call permission scopes plus tunnel-only access give us the audit trail compliance buyers require. |
| 5 | Memory — structured per-client memory files + PostgreSQL session history | Stage 3 / Operational reliability + sovereignty | Alternatives considered: ephemeral chat (no memory); an LLM vendor’s built-in memory feature; single-tenant memory store shared across clients. Vendor memory is a lock-in trap and a sovereignty problem. Single-tenant shared memory leaks across clients. Per-client memory in PostgreSQL is queryable, portable, and isolated by design. |
| 6 | Skills — packaged instruction sets loaded on trigger phrase | Stage 3 / Operational reliability | Alternatives considered: re-prompt for every task; fine-tune custom models per behavior; write task-specific scripts. Re-prompting is inconsistent. Fine-tuning is expensive and hard to version. Skills are declarative, versionable, testable, and load only when the trigger fires — keeping context lean and behavior consistent. |
| 7 | Agents — OpenClaw (self-hosted runtime) for conversational / judgment work; n8n AI Agent nodes for workflow-embedded judgment | Stage 3 / 4 / Sovereignty | Alternatives considered: cloud agent platforms (OpenAI Assistants, vendor agent UIs), or no dedicated agent runtime at all. Cloud platforms hold your conversation history and your client isolation in a multi-tenant database we don’t control. No agent runtime forces every interaction back into a chat or a workflow form. OpenClaw gives per-client agent isolation, paired-device input, and overnight pattern consolidation — capabilities we evaluated against alternatives and adopted because they map to specific outcomes (see §5). |
| 8 | Workflows — n8n as the deterministic rail; pipelines for ingestion, scorecard, close, knowledge refresh, cash forecast, compliance monitor | All stages / Auditability | Alternatives considered: Zapier, Make, Power Automate, custom Python workers, Airflow. The hosted alternatives put your business logic and credentials in someone else’s perimeter. Custom Python and Airflow are heavier than the work demands. Self-hosted n8n on k3s gives us a queue we can rerun, integrations we don’t have to write, and a perimeter we control. |
Two corrections from v1.1:
- Tier 3 said "pgvector"; reality is ChromaDB on a dedicated host. Fixed.
- Tier 7 said "Claude Code for development. n8n AI Agent nodes for operations." OpenClaw is now the named runtime for conversational / judgment work, alongside n8n’s agent nodes for workflow-embedded judgment. Fixed.
The principle the tiers serve: AI for interpretation, code for execution, humans for approval. Each tier exists to make that principle real at production scale, on infrastructure you control, with an audit trail you can show — and each was chosen against alternatives, not adopted by default.
On revisiting these choices. Every entry in this table was an intentional decision at a point in time. We expect to revisit each one as the practice evolves. A model that’s right today may not be right next year. A protocol that’s the open standard today may have a successor. A workflow tool that’s adequate at our scale may not fit a 10× larger one. The discipline isn’t "we chose right and we’re done"; it’s "we chose intentionally, we work the choice, and we change it when reality demands a change." This appendix gets revisited with every minor whitepaper revision.
An aside for the technical reader — the Apple-versus-Cray pattern. Cray built supercomputers that could do extraordinary things if you wrote the right code for them; Apple built systems where the structure made ordinary work reliable at scale. ProjectBits’ AI stack runs both modes by design — Sonnet at design time as the Cray-equivalent (translating a written policy into executable Rego, classifying transactions against a 51-criteria taxonomy, drafting case summaries from a transcript) and OPA at runtime as the Apple-equivalent (enforcing the resulting policy deterministically, every time, with an audit log). The methodology earns its keep by knowing which work belongs in which mode.
The same discipline applies to client work. The engineering practice in this appendix — evaluate alternatives, name the trade-offs, measure outcomes, revisit choices when reality demands it — is the same practice applied at the other end of the engagement: the client diagnostic. When ProjectBits begins a fractional CFO engagement, the diagnostic that opens it follows a 12-section template with the same disciplines: enumerated hypotheses, explicit disconfirming evidence, named load-bearing assumptions, calibrated confidence, peer review structured as stress test, pre-mortem before action, and a decision journal with quarterly retrospective. Tetlock’s calibration research is unambiguous on this discipline: sustained for two years, it produces measurable improvement in diagnostic accuracy. The infrastructure scorecard (61% production-grade and rising) and the client diagnostic template are two faces of one practice — measure the gap, ship the fix, re-score — applied to our systems and to our clients’ books with the same rigor.
Changelog from v1.1
| Change | Why |
|---|---|
| Lead narrative restructured from 8-tier architecture to four-stage data flow | Buyers don’t buy architecture; they buy trustworthy financial data flows. The tiers are proof, not pitch. |
| 8-Tier Stack moved to Technical Appendix | Engineering audience still gets the depth; prospect audience gets the value frame first. |
| Tier 3 corrected: pgvector → ChromaDB on prag | v1.1 was architecturally aspirational; v1.2 names what’s actually running. |
| Tier 7 corrected: "Claude Code for development. n8n AI Agent nodes for operations" → OpenClaw + n8n AI Agent nodes | The conversational / judgment runtime is OpenClaw; we’d shipped without naming it. |
| "Five Finance Fears" replaced with "Five Questions Owners Actually Ask" | Elevation framing over protection framing; matches the questions owners actually open with. |
| Industry-aware classifier surfaced as a primary feature, not a buried mechanic | This is the killer feature for the niche. v1.1 buried it. |
| §Receipts added | The methodology applied to the practice itself — pattern from the companion position paper, scaled for this audience. |
| Bridge to the CFO Operating System ("Book 2") added | Stage 4 has a destination, and the destination has a name. |
| Apple-vs-Cray analogy added to the appendix as technical-reader aside | Per locked feedback_apple_cray_analogy.md; explains the Sonnet-at-design / Open Policy Agent (OPA)-at-runtime split without forcing the prospect-facing pages to carry it. |
| Marketing absolutes softened across the document | Per feedback_no_marketing_absolutes.md: "by design" over "never / always / only"; "is unlikely to survive" over "will not survive"; "designed to be reachable" over "achievable in a single quarter." |
| Image set integrated from NotebookLM-rebranded asset library | 7 visuals embedded (composite + slides 4, 8, 10, 12, 13, 14). All ProjectBits-branded via notebooklm-content/scripts/process_intake.py. Slide 14 is the trilogy unifier — same image appears on /insights/ai-readiness/ and /method/. |